





【EV视界报道】马斯克发推特宣布特斯拉“AI Day”将在8月19日揭开神秘面纱,介绍特斯拉在人工智能领域的软件和硬件进展,尤其在神经网络的训练和预测推理方面。

就像2019年的“Autonomous Day”和2020年的“Battery Day”一样,估计“AI Day”整个发布会将会涉及大量软件、硬件技术细节,以此来向外界“秀肌肉”。
神秘的Dojo计算机芯片
在“AI Day”发布会的邀请函上,放着一张夸张的芯片图。由此猜测,芯片采用非常规封装形式,第一层和第五层铜质结构是水冷散热模块;红色圈出的第二层结构由5x5阵列共25个芯片组成;第三层为25个阵列核心的BGA封装基板;第四层和第七层应该只是物理承载结构附带一些导热属性;蓝色圈出的第六层应该是功率模块,以及上面竖着的黑色长条,可能是穿过散热与芯片进行高速通信的互联模块;从第二层结构的圆形边角,以及拥有25个芯片结构来看,非常像Cerebras公司的WSE超大处理器,特斯拉可能采用了TSMC(台积电)的InFO-SoW(集成扇出系统)设计。

所谓InFo-SoW设计,简单来说就是原本一个晶圆(Wafer)能够“切割”出很多个芯片,做成很多个CPU/GPU等类型的芯片(根据设计不同,光刻时决定芯片类型),而InFo-SoW则是所有的芯片都来自于同一个晶圆,不但不进行切割,反而是直接讲整个晶圆做成一个超大芯片,实现system on wafer的设计。
 这么做的好处有三个:极低的通讯延迟和超大的通讯带宽、能效的提升。
这么做的好处有三个:极低的通讯延迟和超大的通讯带宽、能效的提升。
由于C2C(芯片与芯片之间)的物理距离极短,加上通讯结构可以直接在晶圆上布置,使得所有内核都能使用统一的2D网状结构互连,实现了C2C通信的超低延迟和高带宽;以及由于结构优势实现了较低的PDN阻抗,实现了能效提升。此外,由于是阵列多个小芯片组成,可以通过冗余设计来避免“良品率”问题,以及实现小芯片处理的灵活性。

特斯拉前一阵公布的超级电脑,一共用了5760个Nvida A100 80GB的GPU,在这些芯片之间,需要海量的物理结构进行连接以实现通讯,不仅耗费大量成本,且由于连接结构的带宽限制成为“木桶短板”,导致整体效率较低,并且还有分散的庞大散热问题。
这里拿Cerabraas的WSE-2作为参考对比,一个芯片的核心数是Nvdia A100的123倍,芯片缓存为1000倍,缓存带宽为12733倍,Fabric结构带宽则为45833倍。
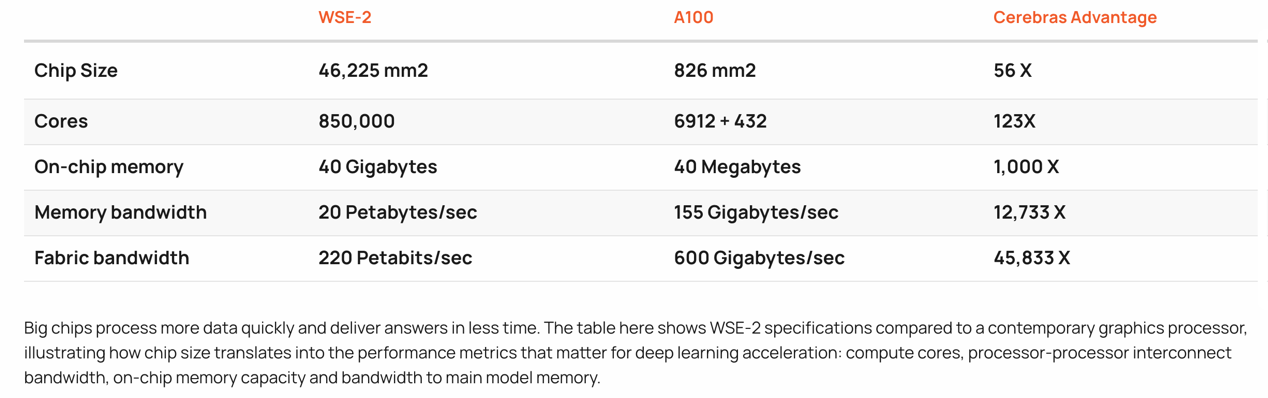 这样级别的性能怪兽其主要目的,就是为了AI的数据处理和训练。其一代芯片WSE,已经有多个重量级用户在使用,比如美国阿贡国家实验室、劳伦斯利弗莫尔国家实验室、匹兹堡超级计算中心、爱丁堡大学的超级计算中心、葛兰素史克、东京电子器件等。
这样级别的性能怪兽其主要目的,就是为了AI的数据处理和训练。其一代芯片WSE,已经有多个重量级用户在使用,比如美国阿贡国家实验室、劳伦斯利弗莫尔国家实验室、匹兹堡超级计算中心、爱丁堡大学的超级计算中心、葛兰素史克、东京电子器件等。
 全球制药巨头葛兰素史克的高级副总裁Kim Branson称赞到,WSE的超强性能将训练时间减少到之前的1/80。而在美国最大的科学与工程研究室阿贡国家实验室,WSE芯片被用于癌症研究,将癌症模型的实验周转时间减少到1/300还少。
全球制药巨头葛兰素史克的高级副总裁Kim Branson称赞到,WSE的超强性能将训练时间减少到之前的1/80。而在美国最大的科学与工程研究室阿贡国家实验室,WSE芯片被用于癌症研究,将癌症模型的实验周转时间减少到1/300还少。
所以不难推断出,“AI Day”邀请函上面放出的这张图,应该就是马斯克所谓的Dojo超级计算机的自研芯片。有意思的是,发布会的时间是2021年8月19日,而就在一年前的8月19日,马斯克发了一条推特说:“Dojo V1.0还未完成,估计还需要一年的时间。不仅仅是芯片本身的研发难度,能效和冷却问题也非常的难。“

之所以说冷却问题难,是因为根据标准晶圆一块是300mm来看,那么特斯拉这块Dojo芯片设计单个芯片应该与RTX 3090差不多,至少每个芯片有280亿-320亿个左右的晶体管,单个芯片功耗可达250-300w左右,整体功耗约在6250w-7500w左右;并且台积电也曾说InFo-SoW设计的最高功耗约为7000w,同样印证了这一点。
几个月后,他又补充道:“Dojo采用我们自研的芯片和为神经网络训练优化的计算架构,而非GPU集群。尽管可能是不准确的,但是我认为Dojo将会是世界上最棒的超算。”并且,马斯克在2021年Q1财报时也曾说:Dojo是一台为神经网络训练优化的超级计算机。我们认为以视频数据处理速度而言,Dojo将会是全世界效率最高的。“

其实马斯克早在2019年“Autonomous Day”就提到过Dojo,称Dojo是能够利用海量的视频(级别)数据,做“无人监管”的标注和训练的超级计算机。
并且如果认真了解过2019年“Autonomous Day”发布会,就会发现,特斯拉推出Dojo超算以及自研芯片,是必然且在规划中的事,是特斯拉不得不去做的事。
为什么要做Dojo?
其实这个问题马斯克曾在推特中回复过:“只有解决了真实世界的AI问题,才能解决自动驾驶问题……除非拥有很强的AI能力以及超强算力,否则根本没办法……自动驾驶行业大家都很清楚,无数的边缘场景只能通过真实世界的视觉AI来解决,因为整个世界的道路就是按照人类的认知来建立的……一旦拥有了解决上述问题的AI芯片,其他的就只能算是锦上添花。”

马斯克已经讲的很清楚了,自动驾驶目前需要解决的难题,其实最核心和最困难的就是“感知”,换句话说系统对周围驾驶环境的感知能力越强,其自动驾驶的综合能力就越强;也就是从这里,行业里分成了两大流派,一个是以特斯拉和Mobileye(同时也有Lidar方案)为首的纯视觉方案;另外是其他所有相关公司,想尽可能加入更多的传感器融合方案。
这里暂且不去讨论究竟哪条路径是正确的,因为很有可能未来实现殊同同归的结果。但无论是哪条路径,都需要对海量的数据进行深度学习,也就是对神经网络的训练,才有可能实现所谓完全自动驾驶,而且这是唯一途径。
原因很简单,自动驾驶的问题,可以理解为处理可能遇到的各种驾驶场景以及做出的操作,那么这个基本是“无限”的;如果有有限的编程方式,那么永远无法解决所有可能遇到的问题,或者说以人类的能力,根本无法覆盖那么多种变化的情况。
早期的各种自动驾驶系统,由于没有别的途径,只能用这样的“死板”方式去研发软件,所以其能力非常有限,只能应付相对稳定和条件限制较多的场景。
而如果想要实现识别各类型的场景,那么就需要这个“软件”不断自我适应和“进化”,这就是利用神经网络进行深度学习的原因了。
神经网络可以简单理解为通过“仿生学”模拟人类大脑皮层的神经元“沟通学习”的方式进行处理数据,用来实现“类人”的学习东西的方式。然而,概念很美好,现实很残酷。
1943年Warren McCulloch和Walter Pitts曾写过论文讲述人工神经网络该如何工作,并且利用电路造了一个简单的模型。后来经过诸多人的努力和研究发展,直到1998年,斯坦福大学的Bernard Widrow和Marcian Hoff才打造出了第一套用于解决实际问题的人工神经网络。
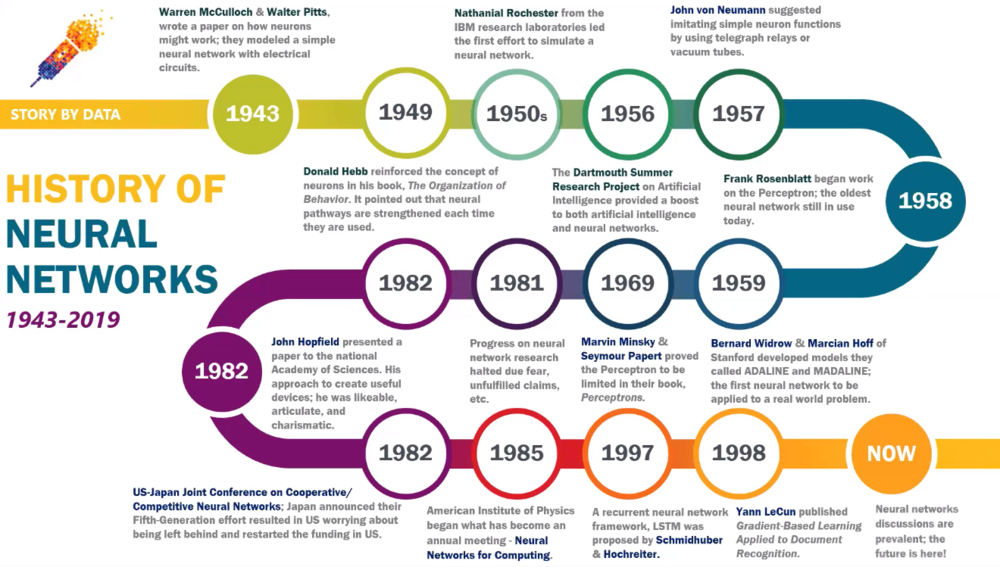
1956年,达特茅斯夏季会议上各路大牛提出了AI定义,大大推动了AI和人工神经网络的发展,也被广泛人为是AI元年。当时人们信心满满,认为不用20年就能打造出跟人脑差不多一样的AI系统。结果在不断研究中发现,深度神经网络的算法太过复杂,从而无从下手。于是放弃了当初“大而全”的目标形式,转为以执行单一目标为方向。
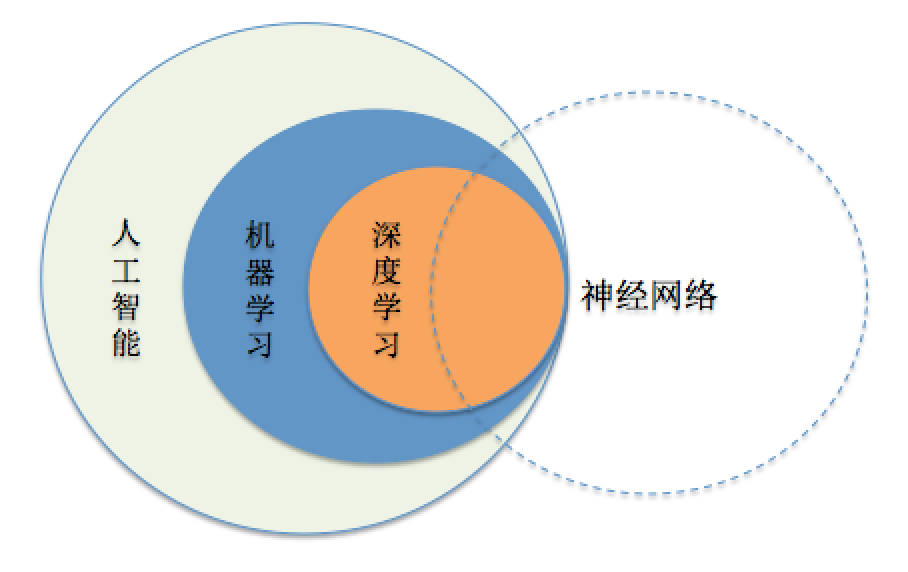
这其中除了因为对人类大脑的认识非常肤浅,以及人工神经网络架构的局限和软件算法的局限之外,更多的就是算力问题,也就是受到半导体行业发展的限制。不同的处理器芯片所具备的能力各不相同。例如CPU更多的通用计算,可以理解为总指挥,负责逻辑上更线性的计算和判断;而GPU则是专职于图像处理的芯片,能够同时吞吐较大的数据量和进行矩阵计算,加之已经是成熟的量产产品,所以被大量应用于AI学习。
而NPU(Neural Processing Unit,神经网络处理器)则是从设计层面就专职为神经网络学习优化的,像谷歌的TPU和特斯拉的FSD芯片都属于NPU序列,这类芯片扔掉了类似GPU中不需要的功能,仅为神经网络所需要的数据处理形式服务,其速度和能效要高很多。
但是,这里还需要区分ASIC(Application Specific Integrated Circuit,专用集成电路)芯片和FPGA(Field Programmable Gate Array,可编程逻辑门阵列)芯片,其中ASIC芯片就是生产后,其运行逻辑和功能就固定了,不能修改,为某项任务(软件)而生,能效极高;而FPGA则是可以通过软件改变其运行逻辑,为半定制的芯片,可以通过软件对其进行修改,适合进行训练和优化所用,能效相比ASIC芯片低一些。像TPU和FSD都属于ASIC芯片,而特斯拉此次发布的Dojo芯片就属于FPGA序列。
回过头来,市场上既没有符合需求的车载芯片可用,也没有符合需求的超算来更好的利用这些数据,特斯拉想要实现这一切,在当时只有自己去做软件和硬件,当年特斯拉在2016年立项做FSD芯片时,谷歌的专属AI芯片TPU才刚刚问世,而车载的AI芯片几乎没有能用的。
所以,当年很可能FSD和Dojo的立项时间不会差太远,只是由于考虑到能耗和需求问题,Dojo等到7nm的技术相对成熟后,才开始逐步推进。
从另一个纬度上去理解Dojo的必然性,是从神经网络学习的计算量级上去理解。在2019年“Autonomous Day”发布会上,特斯拉其实已经明示了会去掉雷达,走向纯视觉,且是视频级别的数据进行直接处理。
举个简单的例子,一张1080p的图像,以最简单的神经网络结构,如果不利用激活函数(tanh、ReLU)进行数据“优化”,其运算量大概需要4万多亿次;即便采用激活函数优化的卷积神经网络处理,其运算量也将达到1.3亿多次;而如果以视频形式处理,一秒按24帧计算,也有24张图像,综合算下来其运算量是惊人的。
值得注意的是,自动驾驶收集的数据中95%左右都是无效数据,也就是对神经网络训练压根没用,简单理解来说就是你每天做几乎相同的卷子,是得不到任何提升的。所以即便特斯拉的车辆仅在特定触发条件下才会收集部分数据,但得到的数据量依然非常庞大,需要Dojo这样为特斯拉自身软件优化过的定制超算,才能大大提高效率。
此外,“无监督训练”也是Dojo的另一个核心目的,用于大幅度提高训练效率。
在神经网络训练中,其实海量的研究人员都是“调参侠”,简单理解也就是通过不断调“权重”来让神经网络判断越来越准确,或者是通过人工标注各种“正确答案”,让其学习。这就会导致“人”成为了效率的短板,从而致使整个过程的训练速度大幅降低。而如果实现“无监督训练”,也就是系统自己通过海量数据和以前“学习”的结果进行自动标注和调整,那么其效率将会是量子级别的提升。
举个简单的例子,谷歌的Alpha Go击败世界围棋大师相信很多人都知道,也是一个人工智能在特定领域击败人类的标志事件。作为对比,Alpha Go经过人工参与调整和标注的训练结果,经历了几年时间击败了全球高手。而作为无监督训练的范例Alpha Zero,仅用三天时间自己与自己对弈,就击败了Alpha Go Lee,在21天打到了Alpha Master的水平,并在40天超越了所有的旧版本。
总结起来,如果特斯拉完成了Dojo的打造,那么就能够以惊人的效率用海量的数据进行训练,解决各种“边缘场景”的问题,加快自动驾驶系统的成熟和完善;更关键的是,特斯拉对其软硬件的垂直整合度非常高,不仅不受制于别人,而且能够以此作为服务,给外界提供深度学习的训练业务。
马斯克曾表示,一旦相对完善了Dojo,将会开放Dojo作为服务给外界提供训练业务,并且Dojo能够承接几乎所有的机器学习任务。 
这也是为什么马斯克敢说,未来特斯拉将会是最大的几家人工智能公司之一。
会有One More Thing吗?
此次特斯拉的“AI Day”,不出意料的话会把Dojo芯片作为最重点的内容进行软硬件的介绍;当然也会覆盖FSD Beta相关的进展介绍,但就目前的信息来看,还极有可能会推出新的基于7nm技术的HW4.0硬件。
毕竟在2019年“Autonomous Day”时,马斯克就说过HW4.0的研发已经进行了一半,所以此次发布会,也很有可能借此机会发布新的车载芯片硬件。
总之,此次特斯拉“AI Day”发布会,很有可能再次在汽车行业甚至是AI领域掀起一波浪潮,至于到底会不会有更多的惊喜,那就到等那天才能揭晓了。




